




Academics are finding new uses for artificial artificial intelligence
{kind=link}
One of the more troubling things you learn about as a student of the cognitive and behavioral sciences is sampling bias.
In statistics, sampling bias is when you make general claims about an entire population based on a sample which only represents a particular chunk of that population.
Imagine somebody pours twenty yellow ping pong balls into a vase, and then twenty blue. If you immediately draw 10 balls from the top of the vase, you might come away with the mistaken impression that all the balls in the vase are blue.
If you give the vase a good shake before taking your sample, then you’ll have randomized it, eliminating the sampling bias.
Similarly, if you’re doing a study of human psychology or behavior, and sample only consists of American undergraduate students who are either: (a) need beer money, or worse yet (b) are required by the same few professors to volunteer as subjects; you might come away with the mistaken impression that all humans are like western undergraduates. In these fields they’ve become the standard subject for the species at large, which is a status they might not deserve.
In a study titled, “The Weirdest People in the World?” researchers conducted a kind of audit of studies that exclusively sample US college students — who, among other similarities, tend to hail from societies that are “Western, Educated, Industrialized, Rich, and Democratic (WEIRD)”. They found that American undergraduates in particular were vastly over-represented:
“67% of the American samples [in the Journal of Personality and Social Psychology in 2008] were composed solely of undergraduates in psychology courses. […] A randomly selected American undergraduate is more than 4,000 times more likely to be a research participant than is a randomly selected person from outside the West.”
They then compared the results of WEIRD-biased studies to studies that researched the same effect, but sampled subjects from non-WEIRD populations.
“The domains reviewed include visual perception, fairness, cooperation, spatial reasoning, categorization and inferential induction, moral reasoning, reasoning styles, self-concepts and related motivations, and the heritability of IQ. The findings suggest that members of WEIRD societies, including young children, are among the least representative populations one could find for generalizing about humans.
“Overall, these empirical patterns suggests that we need to be less cavalier in addressing questions of human nature on the basis of data drawn from this particularly thin, and rather unusual, slice of humanity.”
The problem is, undergrads are easy — they’re around, they’re cheap, they have few qualms about sacrificing themselves for science. They’re at the “top of the vase”. This is called “convenience sampling.”
So how can researchers effectively, and economically, “shake the vase” and get a more representative sample of humans at large? Many think it involves the internet. And a growing number of them think it involves Amazon’s Mechanical Turk.
What is Mechanical Turk?
Mechanical Turk is an online labor marketplace created by Amazon in 2005. Employers post jobs and workers complete them for a monetary reward provided by the employer. It’s sort of like Taskrabbit — an “odd jobs” board with a payroll system integrated — but for virtual tasks. Except with Mechanical Turk, the pay is usually less than a dollar, and the jobs usually only take a few minutes to complete. (The buzzword for this kind of labor exchange is “microtasking.”)
Amazon first developed Mechanical Turk for internal use. There are certain tasks that are easy for humans but difficult for machines. More accurately, there are certain tasks that are easy for humans to do themselves, but considerably more difficult for humans to build machines to do. Ellen Cushing wrote a brief history of the tool in an East Bay Express article:
“In 2005, having built millions of web pages for its various products, [Amazon] was faced with the problem of [identifying duplicates]—a task that, for various reasons, confounded computer algorithms, but that a human could easily do in seconds. […] If computers can’t do the work, why not hire humans to do it for them—to act, essentially, as another part of the software, performing infinitesimal, discrete tasks, often in rapid succession? [Bezos] described it, elegantly, as “artificial artificial intelligence”—humans behaving like machines behaving like humans.”
The Mechanical Turk API integrates the human solutions into an automated workflow. It allows the workers’ — called “turkers” — results to be queried by a software program. So, instead of scanning the pixels in two images and identifying which pixels might indicate shared features between them, Amazon’s algorithm can ask the Mechanical Turk API what percentage of turkers said these images depicted the same object.
Amazon named their invention after a famous 18th Century hoax. “The Turk”, “the Mechanical Turk”, or “the Automaton Chess Player” claimed to be the world’s first chess-playing computer. To onlookers it appeared that a turbaned humanoid automaton had just defeated Benjamin Franklin, or Napoleon Bonaparte at chess. It wasn’t until the accidental destruction of the machine by fire, and 50 years after the death of its inventor, that the Turk’s secret was revealed: its “program” was a human chess master, curled up inside the body of the machine beneath the chessboard, moving the pieces with magnets.
Mechanical Turk’s documentation for employers — called “requesters” in the Turk ecosystem — offers a variety of tasks that the tool could help with, and a variety of case studies for each of them. Turk has been used for: categorization, data verification, photo moderation, tagging, transcription, and translation. Porn sites have used it to title clips, non-porn sites have used it to flag objectionable content. You can buy social media followers on Turk, or retweets. You can spend $200 on 10,000 drawings of “a sheep facing to the left”.

Crowdsourcing the Nature of Humanity

In 2008, a blogger offered turkers $0.50 for their photographs and a statement on “why they turk”
Mechanical Turk launched in 2005, but it took several years to start appearing in academic literature. Then, slowly but surely academics started to realize: one task that can be very, very easy for a human and literally impossible for a machine is the task of being a subject in a scientific study about humans. They also noted that this was a more diverse pool than your standard undergraduate study. But more than that, they noticed these subjects were cheap. Even compared to undergraduates these subjects were cheap.
The earliest studies to incorporate Mechanical Turk evaluated “artificial artificial intelligence” as a possible standard against which to test “artificial intelligence”. Part of natural language processing (NLP) research, and other kinds of AI, is comparing the performance of a program researchers have designed to human performance on the same task. For instance, take the sentence, “I feel really down today.” A human can easily categorize this statement as being about emotions, and expressing a negative affect. A sentiment analysis program would be judged on how well its categorizations match human categorizations. In 2008, a team of natural language processing researchers found that in many cases Mechanical Turk data was just as good as the much more costly tagging and categorization they extracted from experts, (the paper was titled “Cheap and Fast, but is it Good?”)
Then a few studies started cropping up using Mechanical Turk as the laboratory itself, with the turkers as the subjects. In 2009, two Yahoo research scientists authored a paper about how turkers respond to different financial incentives and pointed out that their results probably apply to a broader population — (when incentives are increased people work faster and more, but the quality of work does not improve). This started to pry open the gates. Researchers started using Mechanical Turk to recruit participants to short online surveys, asking them demographic questions and a few experimental questions, and then drawing conclusions from their responses. Others had subjects engage in an online game.
Concurrent to all of these have been a slew of studies about whether this is a valid test population at all.
Testing the Turkers
Researchers already knew that turkers were a very convenient population that had the potential to yield large sets of data. But there are still ways for convenient, large data sets to suck — two kinds of ways: they can be internally invalid or externally invalid.
Internal invalidity is when a study fails to provide an accurate picture of the subjects sampled. Turkers are anonymous and remote from the researchers. Do they speed through experiments without reading the questions or paying attention to the experimental stimuli? Do they participate in the same experiment more than once, motivated by the monetary reward?
In “Evaluating Online Labor Markets for Experimental Research: Amazon’s Mechanical Turk”, researchers checked the IPs of respondents and only found 7 duplicates, accounting for 2% of the responses (14 of 551). “This pattern is not necessarily evidence of repeat survey taking,” the author specifies. “It could, for example, be the case that these IP addresses were assigned dynamically to different users at different points in time, or that multiple people took the survey from the same large company, home, or even coffee shop.”
By default, Mechanical Turk restricts turkers to completing a task only once. Subjects could get around this by having multiple accounts — thus violating their user agreement — but turkers are paid in Amazon payments and would have to have multiple Amazon accounts for this to work. Plus, surveys tend to be considered “interesting” work compared to a lot of the other tasks Mechanical Turk has to offer, so pay for these tasks is not very competitive even by Mechanical Turk standards, which makes them an unlikely target for spammers.
As for whether turkers pay attention — while their “real world” identities are anonymous, they still have online reputations. Requesters rate turkers upon each task’s completion, and can withhold payment if the task isn’t up to snuff. That rating follows a turker around and affects his or her job prospects: many tasks are only open to turkers with a 95% or higher “approval rating”, which is a condition researchers can require as well.
The same researchers noted that when they asked a simple reading comprehension question of turkers, a much higher percentage of them responded correctly (60%) than those given the same survey through Polimex/YouGov (49%) and Survey Sampling International (46%) — suggesting that turkers are more attentive to questions, instructions, and stimuli than subjects in those other samples.
The Micro-Labor Force
External invalidity, on the other hand, is when a study’s results fail to generalize to other settings and samples. Sampling bias threatens external invalidity.
So…what kind of sample is this? Who exactly is filling out these surveys? Who is “inside” the Mechanical Turk?
“MTurk participants are not representative of the American population,” researchers wrote in “Amazon’s Mechanical Turk: A New Source of Inexpensive, Yet High-Quality, Data?”, “or any other population for that matter.”
Initially an overwhelmingly US user base, in 2007 when Amazon expanded to allow Indian workers to recieve their payment in rupees — instead of just Amazon credit, a second kind of turker started to emerge: the Indian turker.
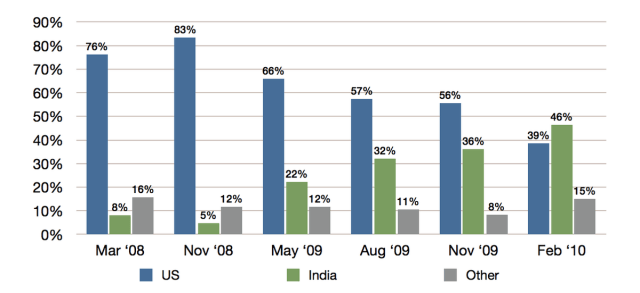
Mechanical turk’s population by country, over time. “Who are the Crowdworkers? Shifting Demographics in Amazon’s Mechanical Turk” Ross et. al. 2010
The contemporary population is about 34% Indian and 46.8% American. These two users work pretty differently — US and other western turkers still do it as a mildly interesting way to pass the time while making very marginal dough.

Survey of turker attitudes, by country. “Who are the Crowdworkers? Shifting Demographics in Amazon’s Mechanical Turk” Ross et. al. 2010
Whereas Indian turkers, and others in developing countries, can take advantage of the exchange rate on American currency to make some reasonable income. Online forums are packed with people strategizing how to make the most of Mechanical Turk for what seem like unworthy returns, until you realize all the posters are in the CST time zone.

Annual overall household incomes of turkers, by country. “Demographics of Mechanical Turk”, Panos Ipeirotis, 2010
According to these communities, fair wage on Mechanical Turk is purportedly ten cents a minute, or $6 an hour. The average monthly wage in India in 2012 fell in the range of $1,006–3,975 annual income per capita. At ten cents a minute, a ‘full-time’ turker could make that in a few months.
But even if turkers in total “are not representative” of “any population”, researchers can slice them down into cleaner demographic samples. Just like they have the option of only allowing turkers with a certain quality score to complete their tasks, they can also do things like only allow US residents. One way to externally validate Mechanical Turk as a tool for science is to compare national surveys of the general population — and other accepted research samples — to the demographics of a Mechanical Turk sample that’s been constrained to match:

Comparing a sample of adult American turkers to other large-scale national samples “Evaluating Online Labor Markets for Experimental Research: Amazon’s Mechanical Turk” Berinsky et. al. 2012
Researchers took a 551 turker sample of American adults, and noted: “On many demographics, the MTurk sample is very similar to the unweighted [American National Election 2008-09 Panel Study (ANESP), a high-quality Internet survey].”
They also noted that “both MTurk and ANESP somewhat under-represent low education respondents” — based on the differences between them and ‘in person’ samples (the Current Population Survey [CPS — a US Census/BLS project], and the American National Election Studies [ANES]). American turkers are also notably younger any of the other samples, which seems to impact other statistics, like income and marital status.

Comparing a sample of adult American turkers to other large-scale national samples “Evaluating Online Labor Markets for Experimental Research: Amazon’s Mechanical Turk” Berinsky et. al. 2012
But when compared to convenience samples — like a college student sample — Mechanical Turk’s advantages really started to shine. The Mechanical Turk sample is “substantially older” than the student sample, and closer to US reflecting demographics. The research also compared it to convenience “adult samples”, from another study and noted that, “more importantly for the purposes of political science experiments, the Democratic party identification skew in the MTurk sample is better.” The researchers pointed out that they didn’t aim to disparage the lab studies. “We simply wish to emphasize that, when compared to the [commonly accepted] practical alternatives, the MTurk respondent pool has attractive characteristics — even apart from issues of cost.”
Experimental Turk
Another way is to validate Mechanical Turk’s use is to replicate prior experiments. “Evaluating Online Labor Markets for Experimental Research: Amazon’s Mechanical Turk” successfully replicates three. “Running Experiments on Amazon Mechanical Turk” successfully replicates three. Not all, but many Mechanical Turk studies ran laboratory experiments parallel to their Mechanical Turk experiments, to compare the data.
In fact, researchers have replicated a lot of experiments on Mechanical Turk. One reason for this is it’s super cheap and — especially compared to the laboratory studies they’re replicating — incredibly, incredibly fast. You don’t need to train and employ research assistants to proctor the experiment. You don’t need to secure a classroom in which to administer it in. You don’t need to offer $20s a student and spend months watching your sample size inch up all quarter and then “boom” as the psych students scramble to meet their course requirements. All you need is an internet connection, and Turk studies tend to take from between a few hours to a few days. $200 can conceivably pay for 10,000 responses, if your experiment is fun enough.
You can find these experiments and their results compiled on the Experimental Turk blog. Many of the recreated studies’ analysis concludes on something to the effect of: “Overall, although our estimate of the predictive power of risk assessment is modestly larger than in the original article, the basic pattern of effects is the same,” — i.e. the Mechanical Turk numbers aren’t identical, but they still agree with the original study’s findings. And according to researchers the variations that do arise are to be expected from the turker sample because turkers are known to be more risk-averse, or younger, etc.
From the blog’s about page:
“[…] as any new instrument, [Mechanical Turk must] be tested thoroughly in order to be used confidently. This blog aims at collecting any individual effort made in order to validate AMT as a research tool.”
The blog is full of links to papers, announcements about upcoming workshops, news clips and informal studies and analyses. Quirks to working with turkers as a subject pool are constantly being discovered — Are they more likely to look up the answers to survey questions online? How do you screen against subjects that have already participated in similar studies? Are turkers psychologically atypical even though they’re not demographically? — and scientists are actively debating how to deal with them.
A Google Scholar search for “amazon mechanical turk” returns over 8,000 articles. Many seem to have moved past the question of whether to use Mechanical Turk as a scholarly tool, and are focused more on how to use it correctly, and when to exercise caution. And many more of them just seem to be using it. It might seem odd, but there’s now a wealth of research that suggests that’s in many ways Mechanical Turk is a step above more traditional methods — including convenience sampling of students and adults, and large internet surveys.
One sure thing is that Mechanical Turk currently offers access to at least two culturally, economically, and politically distinct populations, both adept at the tool and fluent in English. This facilitates international studies comparing effects across populations, which is exactly what researchers say is needed to combat the sampling bias of college student populations. Maybe by adopting an unusual new tool, the cognitive and behavioral sciences will get a little less “weird”.
This post was written by Rosie Cima; you can follow her on Twitter here. To get occasional notifications when we write blog posts, please sign up for our email list