




This post is an adapted excerpt from the blog of Udemy, a Priceonomics customer
Not long ago, the term “data science” meant nothing to most people—even to those who worked with data. A likely response to the term was: “Isn’t that just statistics?”
These days, data science is hot. The Harvard Business Review called data scientist the “Sexiest Job of the 21st Century.”
So what changed? Why did data science become a distinct term? And what distinguishes data science from statistics?
***
The very first line of the American Statistical Association’s definition of statistics is “Statistics is the science of learning from data…” Given that the words “data” and “science” appear in the definition, one might assume that data science is just a rebranding of statistics. A number of Twitter humorists certainly have:
“A data scientist is a statistician who lives in San Fransisco” #monkigras pic.twitter.com/HypLL3Cnye
— Jeremy Jarvis (@jeremyjarvis) January 30, 2014
Data Science is statistics on a Mac.
— Big Data Borat (@BigDataBorat) August 27, 2013
While there’s a grain of truth in these jokes, the reality is more complicated. Data science—and its differentiation from statistics—has deep roots in the history of computers.
Statistics was primarily developed to help people deal with pre-computer data problems like testing the impact of fertilizer in agriculture, or figuring out the accuracy of an estimate from a small sample. Data science emphasizes the data problems of the 21st Century, like accessing information from large databases, writing code to manipulate data, and visualizing data.

A computer from the 1960s.
The arrival of the personal computer revolutionized access to data and our ability to manipulate data. It can be argued that data science is simply a response to this new technology.
The term data science first appeared prominently in legendary computer scientist Peter Naur’s 1974 book Concise Survey of Computer Methods. In the book, Naur defines data science as “The science of dealing with data….” Data science was not just about “analyzing” data (the bread and butter of classical statistics), but about “dealing” with it, using a computer. In Naur’s book, “dealing” with data includes all of the cleaning, processing, storing and manipulating of data that happens before the data is analyzed—and the subsequent analysis.
Though the term data science did not catch on from Naur’s usage, in the 1980s and 90s, an innovative community of people who used computers to “deal with” data blossomed. Groups like the International Association for Statistical Computing and KDNuggets came up with new ways to use computers to find meaning in data.
Several factors prompted these innovations: First, people needed to work with datasets, which we now call big data, that are larger than pre-computational statisticians could have imagined. Second, industry focused increasingly on making predictions about markets, customer behavior and more for commercial uses. The inventors of data science borrowed from statistics, machine learning and database management to create a whole new set of tools for those working with data.
Statistics, on the other hand, has not changed significantly in response to new technology. The field continues to emphasize theory, and introductory statistics courses focus more on hypothesis testing than statistical computing.
Within the field of statistics, some practitioners advocated that the discipline should transform itself to fit the changing landscape. In 2001, the influential statistician William Cleveland wrote a paper that suggested expanding the field of statistics and renaming it “data science.” This new field would include a greater focus on real world “data analysis” and “computing.” Cleveland’s dream never came to pass, but many universities now have data science departments in addition to their statistics departments.
One Twitter quip about data scientists captures their skill set particularly well:
Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.
— Josh Wills (@josh_wills) May 3, 2012
***
Statistician and data visualizer Nathan Yau of Flowing Data suggests that data scientists typically have 3 major skills:
(1) They have a strong knowledge of basic statistics and machine learning—or at least enough to avoid misinterpreting correlation for causation, or extrapolating too much from a small sample size.
(2) They have the computer science skills to take an unruly dataset and use a programming language (like R or Python) to make it easy to analyze.
(3) They can visualize and summarize their data and their analysis in a way that is meaningful to somebody less conversant in data.
Andrew Gelman, a statistician at Columbia University, writes that it is “fair to consider statistics… as a subset of data science” and probably the “least important” aspect. He suggests that the administrative aspects of dealing with data like harvesting, processing, storing and cleaning are more central to data science than hard core statistics.
***
It’s not just hype; data science is in the ascendancy. According to data from the job search website Indeed.com, there were barely any job postings for data scientists before 2011. But by 2015, the demand for data scientists had surpassed the demand for statisticians. The chart below displays the percentage of all jobs posted for data scientists and for statisticians over the last ten years.
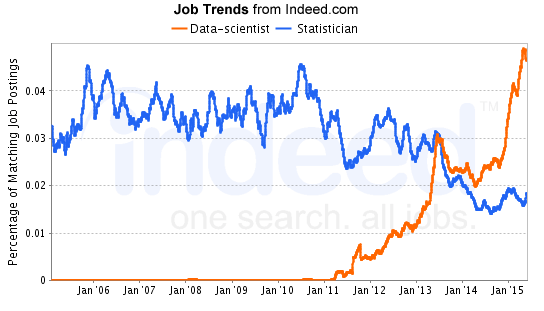
Via Indeed.com
It is likely that some of the positions that, in the past, employers would have listed for statisticians are now listed for data scientists. Some firms use the terms interchangeably. But employers are not merely using new terminology. For data scientists and statisticians, there were more than twice as many jobs listed in early 2015 than there were in early 2012.
Data science jobs are not just more common that statistics jobs. They are also more lucrative. According to Glass Door, the national average salary for a data scientist is $118,709 compared to $75,069 for statisticians.
***
Arguments over the differences between data science and statistics can become contentious. When the term “data science” came to prominence around 2011, there was a backlash. One well-known statistician referred to the position of a data scientist as “just the hip new name for statistician that will probably sound stupid 5 years from now.”
But data science and statistics both continue to exist, and there is no indication that either will go away. Although a great deal of overlap exists between the disciplines, data science developed for good reasons. For the most part, statisticians chose not take on the data problems of the computer age.
Our next post is about the economics of developing a new, male contraceptive technology. To get notified when we post it → join our email list.