




Usually when we embark upon a data crawling or analysis project, it’s because one of our customers is interested in collecting data from the web. Sometimes, it’s because we have a question that we’d like to see answered.
In this case, we were curious which XKCD comics are the most popular of all time. We thought we’d use this as a simple primer for how you can use the Priceonomics Analysis Engine, a tool to help you crawl and analyze web data. The crawler we’re about to illustrate is simple — it really just crawls one page — but it’s a pretty good place to start.
For those who are unfamiliar with it, XKCD is a web-comic by Randall Munroe, known for its distinctive illustration style and geek credibility. The comics are extremely effective at illustrating various human and technological phenomena, and as a result get shared a lot. While we can’t directly see which XKCD comics have the most traffic, we can use the Analysis Engine to discover which have the most social shares.
In most web crawling endeavors, there are three stages: First, write a crawler that browses a site and builds a list of all the URLs you want to examine. Second, fetch the HTML from those URLs. Third, analyze the HTML.
In this XKCD example, we’ll figure out the best way to enumerate all the available comics, and then analyze how many social shares each comic has in order to determine the site’s most popular comics. You can sign up for a free Analysis Engine developer key to replicate this analysis or conduct you own. Visit the API documentation for more detail on how to interact with each piece of the API.
For those of you who just want to see to a list of awesome comics, feel free to skip to the end. Onward!
Preliminaries
Our demo code is written for Python 2.7 and runs on Ubuntu 14.04 LTS. It’s also available in our public GitHub repository under the Apache License v2.0. To keep things simple, there is no error handling in the code and it hasn’t been optimized for performance or multithreading. The Python script is located at demos/xkcd/xkcd_simple_demo.py in the repository.
Methods for crawling through a website
There are generally three ways to crawl through a website:
1) Start at a “seed” page, and recursively follow all (or a subset of) internal links.
2) Identify a pattern in the URL for pages you want, then generate URLs as needed. If you know the range of valid IDs for XKCD comics, you can correctly guess the URL for all of them.
3) Read the website’s sitemap (essentially a list of all pages on a website) and choose which links to follow.
Luckily, XKCD is one of those websites where you can use any of these three methods.
If you wanted to visit each comic individually, you could write a crawler that starts with today’s comic and just follows the “PREV” link on each page until there are no more left to crawl. Or, you could simply increment the comic ID from 1 to 1474 in the URL http://xkcd.com/[comic_id]/.
Best of all, all 1,474 comics are listed here in the Archive, so we’ll use the analysis engine to fetch and analyze those links.
Creating a Framework
We start by importing several python modules — the requests, json, and csv modules. If you don’t have the requests module installed, you can use pip to get the module. The csv module isn’t necessarily required for our API requests, but we will be using it later for output.
Now we specify some global variables: our API key; the headers for our request where we send the API key; an outer schema which is shared for all types of requests; the base URL for API calls; the output file name.
After that we’ll specify our generic function for making API requests. This function takes an app name and some data for the request, and uses that information to call the API. Our API is a REST API that always returns valid JSON, so we can let the requests module parse the returned data for us.
Fetching the HTML
First, we’re going to fetch the archive page by using the Fetch app. We use Fetch for making HTTP requests because it allows us to do useful things like understand robots.txt, route requests from around the world, and more. The XKCD archive page contains the URLs of all the comics, as well as the names of each individual comic. We can do this in a few simple lines:
Analyzing the HTML
After we’ve collected the HTML from the archive page, we need to extract the comic links. The Links app is perfect for this – and it lets us filter the links with a regular expression! We then select the links, sort them, and print how many XKCD comics we found.
Getting Social Data
With the URLs we’ve acquired, we can now get social media data from the Social app. This app conveniently collects data from several social media APIs including Facebook, Twitter, Reddit, and others. All you need to do is give it a URL, and it returns the appropriate data.
This does come with one caveat: as per the API documentation, you should handle a situation where one or more of the social APIs return None.For the sake of clarity, we’ve forgone error handling in this demo. However, you should be aware of this if you plan on running the code, as you may end up with some skipped comics, or comics that only have some of the providers. We will be showing some error handling in the next post of this series.
To collect all the social data, we iterate over the comic URLs we collected previously. For each URL, we call the Social app and store the result. This snippet, combined with the basic framework posted above, should work for pretty much any list of URLs you want to pass into it.
Output
If we were to print out one of the JSON results, it would look something like this:
This would be great if we were going to store our data in, say MongoDB or in a PostgreSQL JSONB datastore. But since this is meant to be a simple example, we will just store it in a CSV file.
To make the data useful we will start by throwing in a pinch of metadata (the comic names) that we collected earlier. Now we flatten the dictionary by looping over the “data”:“stats” part of the result to extract all the data from each service. Due to the fact that we did not handle errors while fetching social data earlier, some of the nested directories may contain a None value (if you are new to Python, None = null). Therefore, when we loop over the various providers in the stats, we check if there are metrics and store those in our row dictionary if they exist.
Our flattened dictionary ends up looking like this:
For the next step, we convert any unicode strings into UTF-8 bytestrings for output. We have to convert the strings because the Python’s built-in csv writer does not handle unicode strings particularly well.
Last but not least – we need to actually write out the flattened dictionaries to a file. Python’s csv.DictWriter class does a great job of mapping the data, so we just feed it some headers and let it run on the list of dicts.
So, what’s the most popular XKCD Comic of all time?
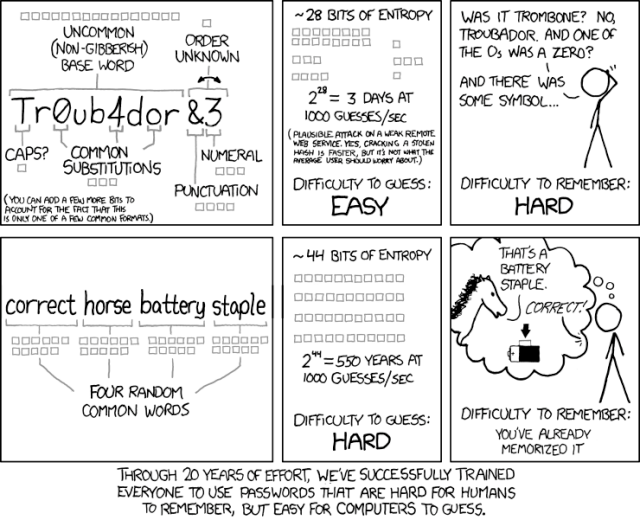
Here’s the raw data of how many social shares every XKCD comic has ever gotten. The most shared comic on Twitter is this excellent primer on passwords:
On Facebook, however, the most shared post of all time is about privacy opinions:

On Pinterest, the most shared comic of all time involves cat food, of course:

On LinkedIn, the most popular comic is an explanation of the Heartbleed Bug. And on Reddit, the epic comic “Click and Drag” has accumulated the most points. It’s hard to describe what that comic is about — just check it out.
So, here is a list of all 1474 XKCD comics, sorted by their popularity on the major social networks. Feel free to start at the top and spend all day clicking through and reading. If you have any data crawling needs, feel free to check out the Analysis Engine or have our data services team help you out.
This post was written by Elad Yarom and Rohin Dhar. For updates on the API and Analysis Engine, join our developer email list.