




This post is an adapted excerpt from the blog of Amplitude, a Priceonomics customer.
A lot of early web developers did not mess around much with analytics tools. The mid to late 90’s saw the rise of the extreme-amateur web developer: X-Files fans who filled pages with photos of every moment of visible romantic tension between Scully and Mulder; teenagers with livejournal accounts about being teenagers with livejournal accounts; retired conspiracy theorists.
It wasn’t so much that these developers weren’t ready for web analytics as it was that web analytics wasn’t ready for them: most solutions to monitor site traffic were expensive, complicated, or both. For the most part, amateurs were OK with this. Their pages were relatively simple, and their traffic relatively low, so they weren’t too worried about monitoring performance. And, back then, analytics was mostly thought of as a tool to track bugs and prevent server failure.
However, this did leave these amateur web developers with one, obvious, burning question: How many people are looking at my website?
Enter the hit counter: basically the bluntest web analytics solution ever provided.
Hit counters purported to display how many people had visited a site since the hit counter was placed on the site. They usually were image files vaguely resembling odometers. Hit counters were about as hackable, breakable, and ugly as they were easy to install. But don’t be too hard on them: they set the stage for present day web analytics.
Server Log Software
The earliest state of the art analytics solutions depended on reading and analyzing the server log. Every time someone views your web page, their browser makes an HTTP — hypertext transfer protocol — request for every file on your page, to the server each file is hosted on. A record of each request is kept in the server log.
Server log records keep track of many useful things: the person’s IP address, a timestamp of the request, the status of the request (whether it was successful, timed out, etc.), the number of bytes transferred, and the referring url — the page the window displayed before making a request for your file.
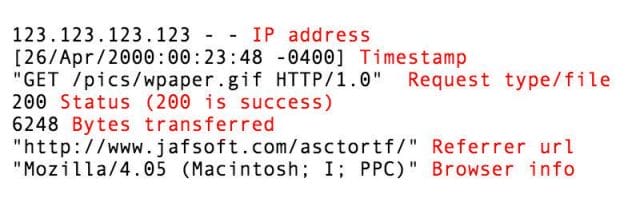
Breakdown of a fictional line of server log: [123.123.123.123 – – [26/Apr/2000:00:23:48 -0400] “GET /pics/wpaper.gif HTTP/1.0” 200 6248 “http://www.jafsoft.com/asctortf/” “Mozilla/4.05 (Macintosh; I; PPC)”] via jasoft
Early analytics solutions were programs that took every entry in the server log and helped you interpret them. The log could tell you whether your server saw much heavier traffic at certain points in the day, which you needed to do a better job of accommodating, as many requests failed. A good log analysis software could also help you pick out the requests made by bots and crawlers from those made by human visitors in the log — that’s good both if you’re worried about being crawled, and if you want accurate data on the people who view your site. The log could also tell you who drove the most traffic to your site, or if somebody new was linking to you.
Though the server log had potential for sophisticated analysis, in the early 1990s, few sites took full advantage of it. Web traffic analysis typically fell under the responsibility of the IT department: The server log was handy when managing performance issues and keeping websites running smoothly. “Companies typically didn’t have defined site goals and success metrics,” a writer at marketing blog ClickZ observes. “Even if they did, very rarely was the tool set up to track those key metrics.”
Not all was well with this analytics solution. Server logs got harder and harder to interpret meaningfully as the web developed. In the earliest days, most urls only hosted a single html file of plain hypertext, so one pageview generated one HTTP request. But once pages started to have other files embedded in them — images, audio files, video — that resulted in multiple HTTP requests per page visit. Also, as browsers became more sophisticated, they developed a technique called caching: temporarily storing a version of a file in the system cache, to get around issuing requests over and over again for repeated visits. Because a new HTTP request wasn’t being issued, these repeated views didn’t show up in the server log.
In 1997, with existing tools, it could take up to 24 hours for a big company to process its website tracking data. Server log analytics companies hussled to keep up with the rate at which the web was growing, with varied success. Others started looking elsewhere, and in the late 1990s, a solution arose from an unlikely place: the Internet of amateurs.
Enter the Hit Counter
Amateur web developers — the kind who built websites to showcase their pez dispenser collections — tended not to do much with their server logs. First of all, they often hosted their sites with free providers that didn’t give them access to their server logs. But even if they had access, there wasn’t much incentive for them to fork over a couple hundred dollars for log analysis software, or to learn to use the complicated free versions.
Their websites worked fine, they just wanted to know how many people had looked at them. That is where the hit counter came in.

A subset of the variety of hit counter styles still available to you, if you want one for some reason
Hit counters — also known as web counters — were chunks of code that used a simple php script to display an image of a number, which incremented every time the script ran. It wasn’t a sophisticated metric, and often kind of obtuse, but hit counters were damn easy to use, even if you knew next to nothing about the web. A user could simply select a style they wanted from the hit counter website, and then copy-paste the generated code.
Some hit counters were better than others. Later hit counters came with a hosted service, which let you log in to see slightly more sophisticated website stats than the basic hit count, but most only showed you the aggregate “views” of your webpage since the hit counter was installed. If you wanted to know how many views your site had in the past week, you had to have a record of what the hit counter was at a week ago and subtract. Hit counters were also notoriously easy to “hack”: many a web developer spent his afternoon hitting “refresh” and incrementing the counter to make his site look popular. They did a variable job of filtering out HTTP requests from bots. On top of this, a lot of hit counters were SEO spamming techniques: they would hide links in the copy-paste code, to get lots of link referrals for other sites.
Despite their shortcomings, hit counters were an improvement on server log analysis in a few very important ways.
First of all, server log analysis required website owners to have access to their server log files, and to know how to manage that data and interpret it. Hit counters introduced a way to automatically send the data to somebody else to analyze. Because the hit counter images were hosted on a website owned by the people who made the hit counter, the HTTP requests for these images ended up in their server logs. The data was now successfully being gathered, stored, and interpreted by a third party.
Second, a website owner did not need to know what they were doing to read them. They might misinterpret the data, or miss a lot of its nuance, but it was clear hit counter was at least supposed to estimate: how many times people have visited this website. Most of the time this was not useful data, but it made many an amateur feel like they were part of the World Wide Web. And when their site did experience a relative surge in traffic, they had a means to discover it.
Javascript Tags

A tagged butterfly, photo by Derek Ramsey
{kind=link}
Hit counters were a primitive example of web page tagging, which is a technique employed by most analytics software today. In field biology, tagging is when an animal is outfitted with a chip or label, which can be monitored as a means of tracking the animal. Web analytics tagging is similar. The “tag” is a file — the images in a hit counter script, for example — embedded in the web page’s html. When someone HTTP requests a page, they also HTTP request the tag, sending data about the user and the request to whomever is collecting the data for analysis.
Later analytics tags developed to use more sophisticated scripts — usually written in Javascript — to send along different information than HTTP requests. Tag-based analytics can track more flexible information, like how much somebody is purchasing an item for, or the size of their screen. They can also monitor interaction with specific elements on the page.
In the late 1990s, tagging-based analytics companies started to proliferate. Some of these sold software similar to the old server log analytics packages: they used tags to track user behavior, but sent this data to a client-hosted and client-managed database. More common, though, were web-hosted-tag-based analytics solutions — which stored your data in a web-hosted database, owned and managed by the analytics company. This was a much cheaper and easier-to-implement solution for the rapidly growing number of smaller tech companies.
These solutions also tended to come with simpler, less-technical interfaces than server log programs. Parallel to its technological transformation, analytics was also undergoing a massive cultural shift.
“Marketers [were] starting [to think] of ways they could use this data if they had better access to Web analytics,” ClickZ chronicles. But, starting out, they usually didn’t know what questions to ask, or how to answer them. Their companies’ understaffed IT departments often ran out of the resources and patience it took to help them. These new tagging-based analytics tools took the reliance off of IT, the servers, and log file processing. From ClickZ:
“Suddenly interested marketers could go to one of those companies, have some basic tags placed on the site, and get more accurate data. It looked like all the issues were solved, and [marketing departments] could finally get the information they needed — still rarely tied to overall business goals, but a step in the right direction.”
This was the first major step towards the data-centric attitude about product, marketing, user experience, and design that dominates today’s Internet and tech culture. So the next time you run across a website with an old fashioned hit counter, take a moment to appreciate an important historical artifact: these ugly little image files helped make web analytics, and thus the web, into what they are today.
To get occasional notifications when we write blog posts, sign up for our email list.